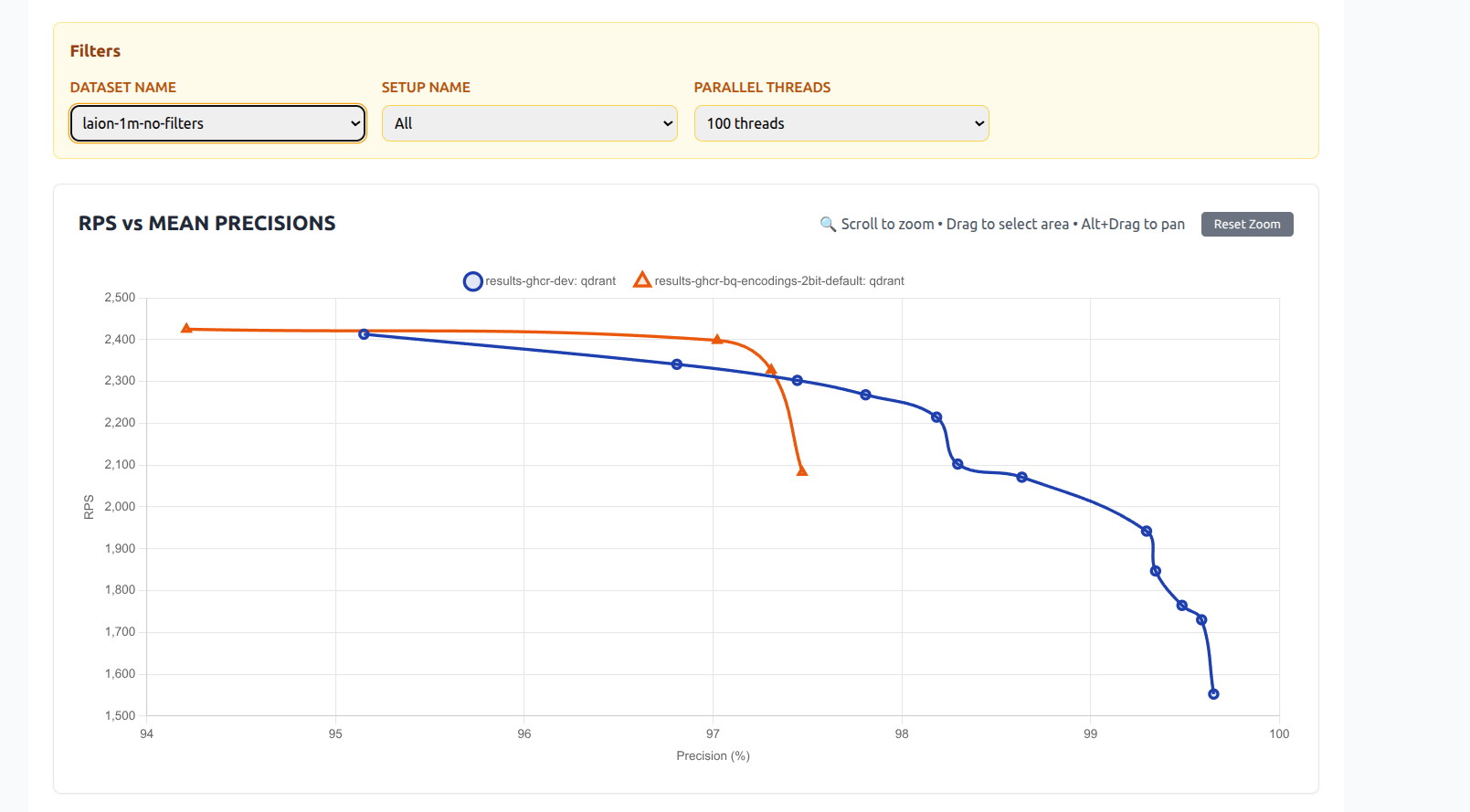
Benchmark Results: 2-bit vs 1-bit and Scalar Quantization
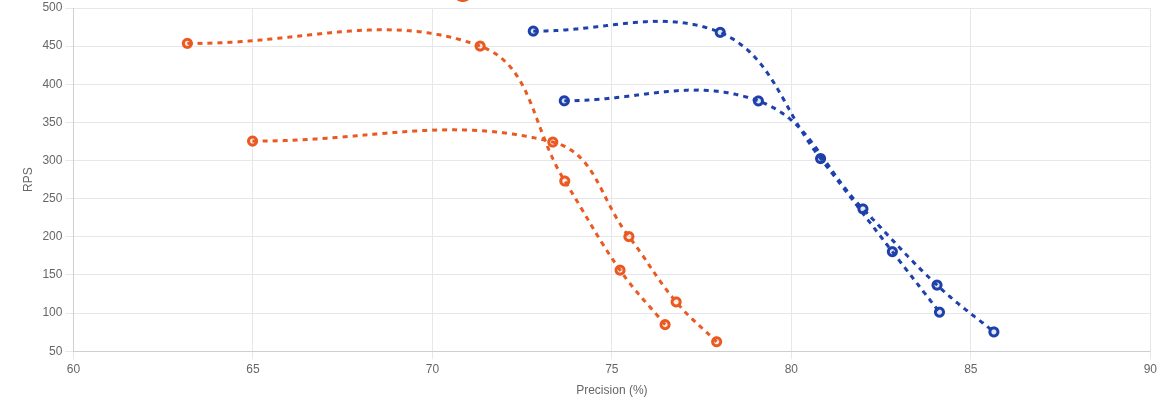
We ran extensive benchmarks to compare the new 2-bit quantization with both traditional 1-bit (binary) quantization and scalar quantization (e.g., 8-bit). Dataset: Laion 1 million 512d vectors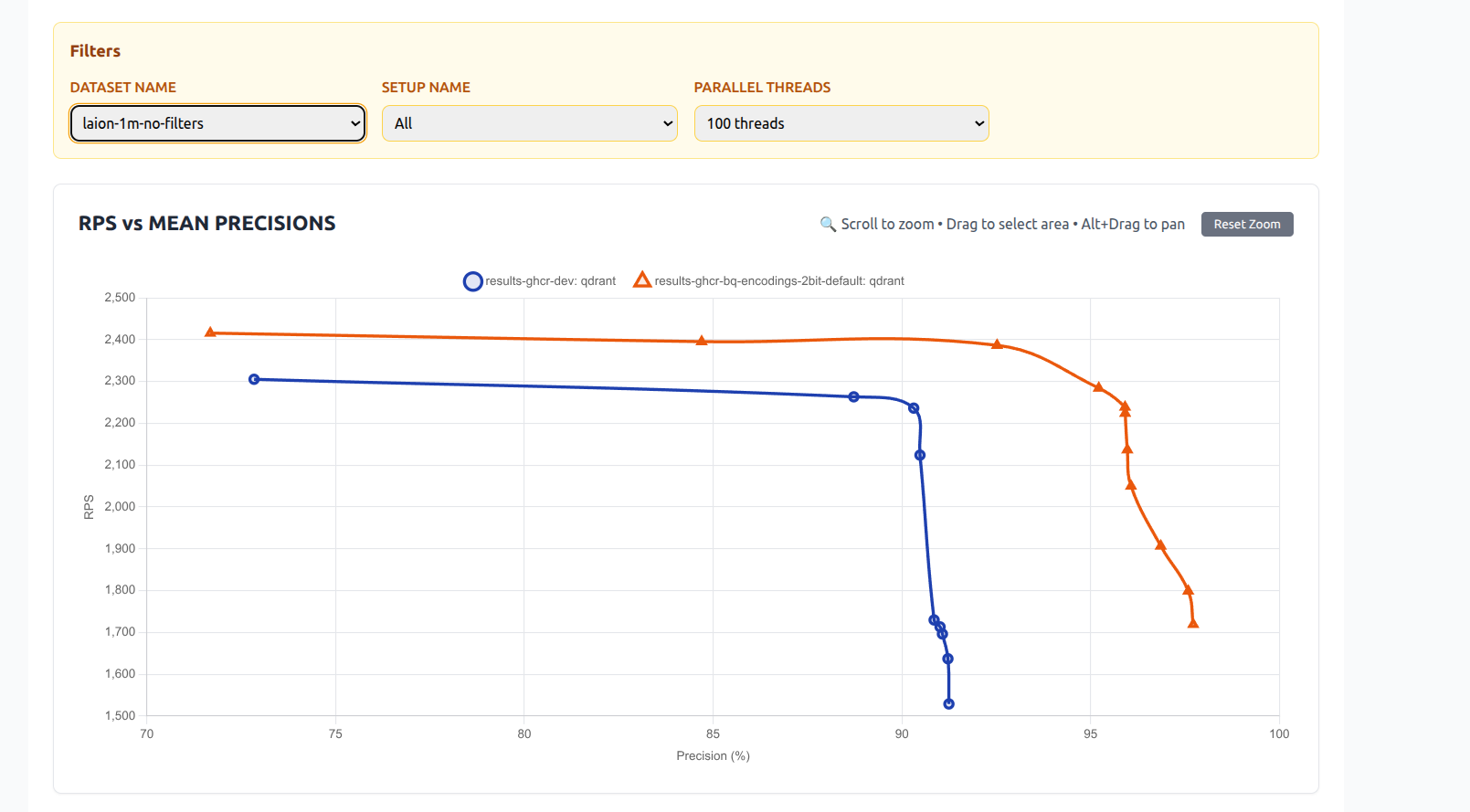
2-bit VS 1-bit Quantization
2-bit VS Scalar Quantization